系统地总结一下Android性能优化关于UI优化方面的知识点。
16ms原则
UI的优化就是对卡顿问题的优化,首先了解一下Android的渲染流程:
1、CPU计算数据
2、GPU对数据进行渲染,放到buffer里存起来
3、显示器把buffer的数据显示出来
我们都知道要为了UI的顺畅需要保证一次的渲染在16ms之内,这是为什么呢?
Android手机的屏幕刷新率一般是60HZ,也就是1s刷新60次,每16ms刷新一次把图像显示在屏幕上。这就要求我们的UI绘制一定要在16ms内完成,否则就会看到两帧同样的画面,也就是掉帧。
我们经常看到如下图,也就是UI正常渲染的情况:
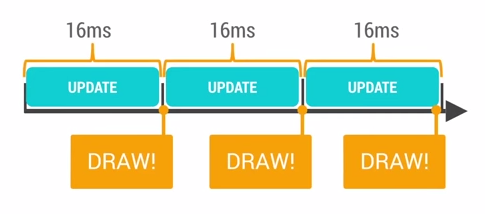
最初看到这张图的时候就有一个疑问,屏幕每16ms刷新一次,但是触发绘制的时间点是不确定的呀。如果恰巧在一帧的结尾触发了绘制(比如调用了invalidate),这时屏幕取出的数据肯定是上一帧的,不也会掉帧吗?
要弄清这个疑问就需要对Android的绘制流程进行一个梳理:
在Android 4.1之后引进了VSYNC和双重缓冲的技术大大增加了UI的流畅度,实际上渲染的流程可以用下图更精确地表示。
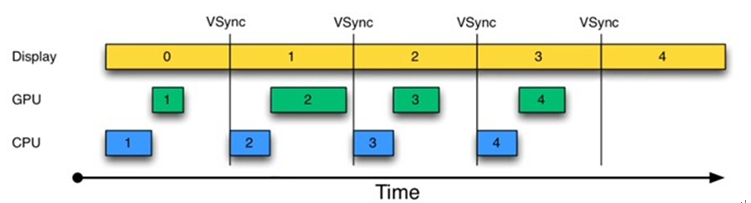
如上图,屏幕每隔16ms都会发出一个VSYNC信号,app层接收到垂直同步信号之后CPU开始计算数据(measure、layout、draw)、GPU渲染图像。等到下一个VSYNC信号到来时,将上次渲染的图像显示出来,再继续进行下一次的渲染。从图上看来,每次的绘制都是精确地在VSYNC信号到来时,并不会出现刚刚说的在一帧的结尾进行绘制。
那么Android源码中是怎么实现垂直同步信号控制App层的绘制的呢?
首先从一个能触发UI绘制的方法入手 View#invalidate
从源码中可以看出View#invlidate会层层向上找parent,最终找到ViewRootImpl类的invalidateChildInParent方法,该方法中的主要逻辑是调用了scheduleTraversals()
ViewRootImpl#scheduleTraversals
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
}
}
在L6向 Choreographer中post一个Runnable:
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
ViewRootImpl#doTraversal
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().removeSyncBarrier(mTraversalBarrier);
if (mProfile) {
Debug.startMethodTracing("ViewAncestor");
}
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "performTraversals");
try {
performTraversals();
} finally {
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
if (mProfile) {
Debug.stopMethodTracing();
mProfile = false;
}
}
}
Trace.traceBegin和Trace.traceEnd是framework中添加的分析方法,后面可以帮助我们分析耗时等,在framework的很多地方都有类似的调试方法。
ViewRootImpl#performTraversals
private void performTraversals() {
//省略大量代码...
performMeasure();
performLayout();
performDraw();
}
最终可以得出结论,这个Runnable执行的结果就是开始绘制整个View视图。
接下来看看Runnable是什么时候执行的,post方法最终进入Choreographer#postCallbackDelayedInternal。
Choreographer#postCallbackDelayedInternal
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
//...
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
scheduleFrameLocked(now);
}
}
L6将Runnable放入队列中,然后调用了scheduleFrameLocked(now)方法,继续追下去:
DisplayEventReceiver#schedulVsync
/**
* Schedules a single vertical sync pulse to be delivered when the next
* display frame begins.
*/
public void scheduleVsync() {
//...
nativeScheduleVsync(mReceiverPtr);
}
接下来就调用了native方法,追踪不下去了,从方法的注释来看好像是在告诉底层: 下一帧来的时候给我安排一个VSYNC信号。
回头再继续看队列中的Runnable什么时候被取出来执行了,经过梳理发现调用的根源为:
DisplayEventReceiver#dispatchVsync
// Called from native code.
@SuppressWarnings("unused")
private void dispatchVsync(long timestampNanos, int builtInDisplayId, int frame) {
onVsync(timestampNanos, builtInDisplayId, frame);
}
FrameDisplayEventReceiver#onVsync
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource);
}
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
mTimestampNanos = timestampNanos;
mFrame = frame;
//画重点:向主线程发送message
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}
Choreographer#doFrame
void doFrame(long frameTimeNanos, int frame) {
//省略大量代码
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
}
继续调用:
void doCallbacks(int callbackType, long frameTimeNanos) {
callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(
now / TimeUtils.NANOS_PER_MS);
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW,CALLBACK_TRACE_TITLES[callbackType]);
for (CallbackRecord c = callbacks; c != null; c = c.next) {
if (DEBUG_FRAMES) {
Log.d(TAG, "RunCallback: type=" + callbackType
+ ", action=" + c.action + ", token=" + c.token
+ ", latencyMillis=" + (SystemClock.uptimeMillis() -c.dueTime));
}
c.run(frameTimeNanos);
}
}
}
至此,从CallbackQueue中将之前添加的CALLBACK_TRAVERSAL类型的任务取出、执行,进入绘制流程。
总结一下:
1、应用中调用刷新时,将遍历View树的操作封装在Runnable里,然后放到Choreographer队列中,并且通知底层安排下一帧的VSYNC信号。
2、每隔16ms屏幕的VSYNC信号到来时,从队列中取出Runnable执行,绘制、渲染View树。
3、一帧的时间内调用多次绘制方法,只有第一次生效,会添加一个绘制任务到队列中(因为有mTraversalScheduled变量的控制。其他的绘制也没必要,绘制时会遍历整棵View树)。
卡顿原因
基于对上面UI渲染流程的梳理,可以找到造成一帧绘制时间超过16ms的点:
1、主线程进行耗时操作导致绘制操作迟迟不能进行,可能原因:
-
主线程在执行其他的耗时操作,导致接收到VSYNC信号时不能及时处理doFrame的message。
@Override public void onVsync(long timestampNanos, int builtInDisplayId, int frame) { mTimestampNanos = timestampNanos; mFrame = frame; //画重点:切换到主线程 Message msg = Message.obtain(mHandler, this); msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS); } @Override public void run() { mHavePendingVsync = false; doFrame(mTimestampNanos, mFrame); } -
输入操作和动画操作在主线程耗时。
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos); doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos); doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
2、CPU绘制耗时过长,可能的原因:
布局层级复杂导致measure、layout等需要更长的时间、
自定义控件onMeasure、onLayout、onDraw逻辑有问题(可能有耗时操作?)
3、GPU渲染耗时过长,可能的原因:
1中绘制的View树复杂,导致GPU需要执行更多的命令来渲染一帧、
自定义View draw逻辑复杂
卡顿检测
1. GPU渲染模式分析
直观地看出哪里出了问题
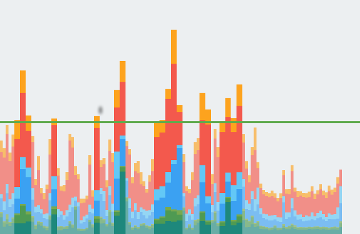
每个色块的含义如下:


Misc: 主线程在执行耗时操作导致VSync到来时不能及时执行绘制渲染
Input: 事件回调耗时太多(比如move-> scroll 触发RecyclerView滚动时inflate)
Anim: 动画回调耗时太多(比如fling动画触发RecyclerView滚动时inflate)
Measure/Layout: 1、布局复杂 2、double taxation 3、onLayout和onMeasure执行耗时操作。
Draw: onDraw做了耗时操作。
Sync&Upload: Android5.0之后UI的绘制和渲染在不同的线程中,主线程进行UI的绘制,创建DisplayList ,RenderThread 进行UI的渲染。 主线程的bitmap需要上传到GPU的内存中进行绘制,如果此条过高说明有大量图片。
Issue command: RenderThread将DisplayList的OpenGL绘制命令进行优化之后发送到GPU,此条过高可能是因为绘制的命令非常多
Swap buffer:CPU等待GPU完成工作的时间,过高表示GPU正忙。
2. systrace
Android SDK tools中提供的工具,相比GPU呈现模式分析,提供了一些更加详细的详细数据帮助我们分析系统的状态,分析卡顿原因。
Android在Framework的关键代码中添加了 Trace.traceBegin 和 Trace.traceEnd 方法,此工具就是把这些方法收集的信息抓出来,便于我们分析应用的运行情况。
简单的使用方式:
```shell
python systrace -l #查看支持抓取的种类
python systrace [view,gfx,sched] -o [output.html]
open [output.html] #查看trace文件
```
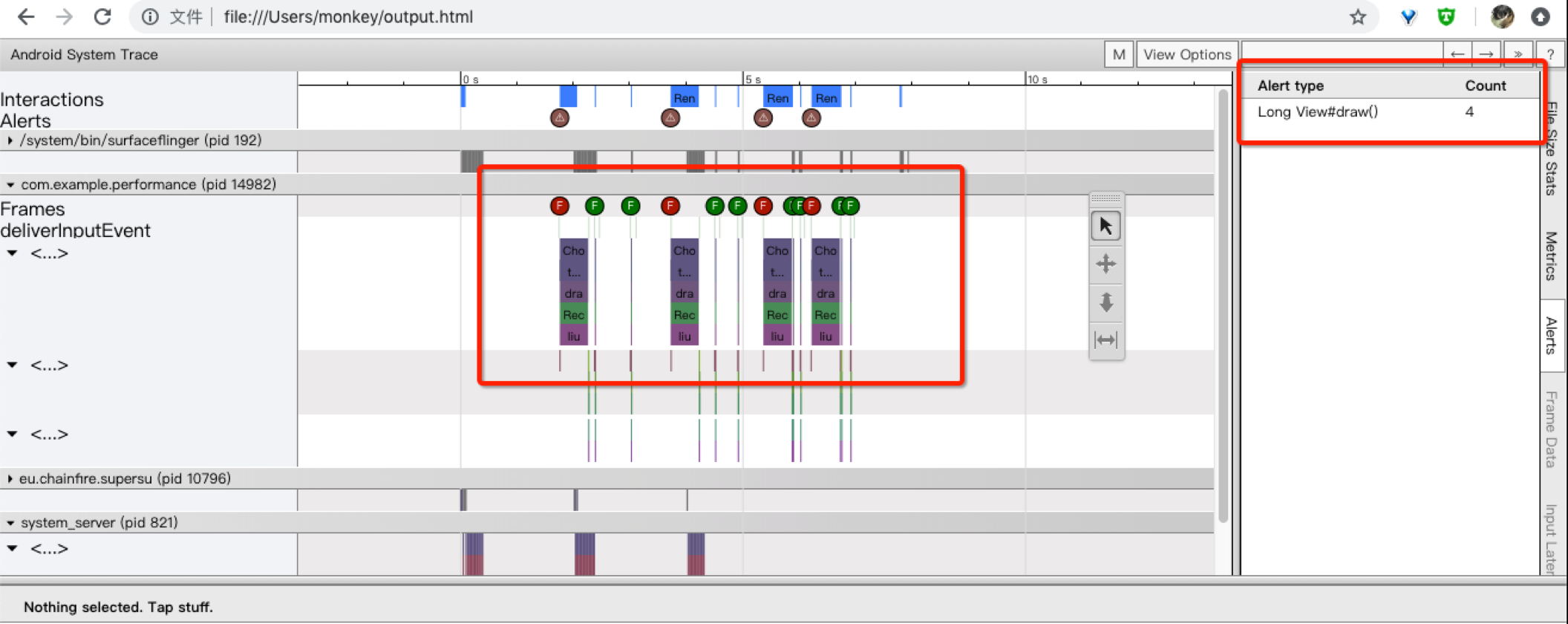
一些关键点:
右侧的Alert提示卡顿出现的点和原因。
中间红色的F代表出现卡顿的帧,可以查看在哪一步消耗了多长时间。
右上角?查看操作快捷键
3. Android CPU Profiler
记录详细的调用栈,进一步统计方法的时间消耗,定位问题代码的位置。

4. GPU过度绘制分析
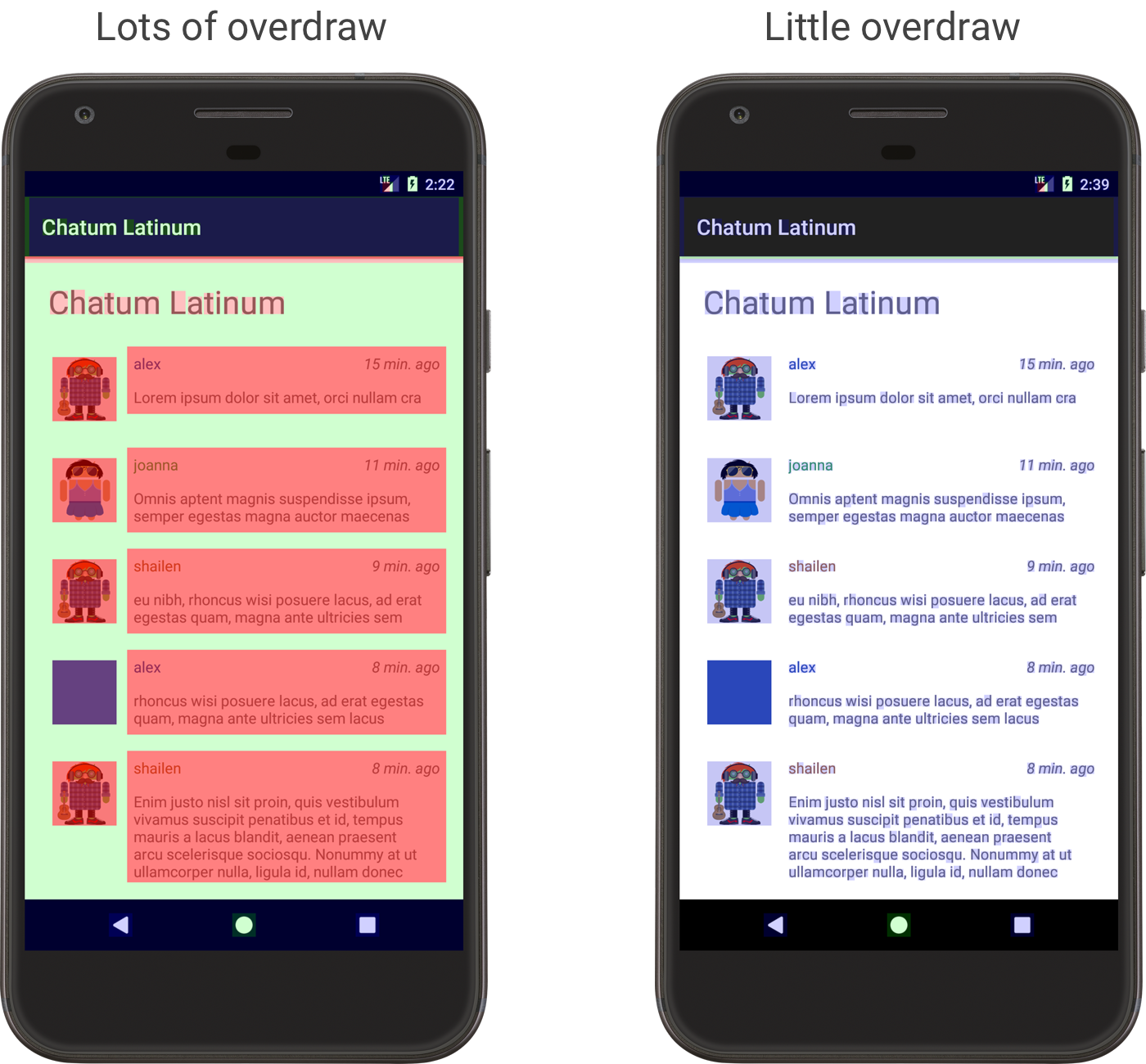
- 真彩色: 没有过度绘制
- 蓝色: 过度绘制 1 次
- 绿色: 过度绘制 2 次
- 粉色: 过度绘制 3 次
- 红色: 过度绘制 4 次或更多
有些过度绘制是避免不了的,但是要尽量做到真彩色和蓝色。
5、通过代码检测
BlockCanary
原理:
Looper#loop()
```java
for (;;) {
Message msg = queue.next(); // might block
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
// ignore some code...
}
```
Choreographer
```java
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
@Override
public void doFrame(long frameTimeNanos) {
}
});
```
6.Lint工具
最佳实践
CPU绘制阶段优化(measure/layout/draw阶段)
主要是减少布局的层级
1、RelativeLayout还是LinearLayout?
RelativeLayout或者LinearLayout使用weight会测量两次
如果RelativeLayout嵌套RelativeLayout会导致子View测量更多次
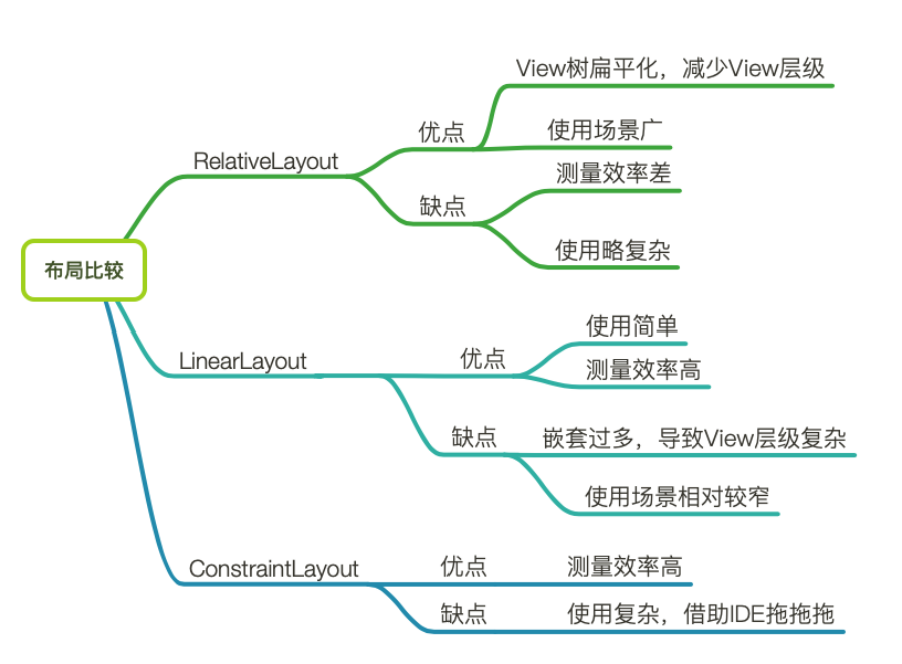
建议:
a、使用RelativeLayout来减少View层级,使View树扁平化。
b、如果层级相同,优先使用LinearLayout
c、考虑使用ContraintLayout
2、减少无用的嵌套布局
```xml
<LinearLayout
android:layout_width="wrap_content"
android:layout_height="wrap_content">
<ImageView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:src="@drawable/test" />
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content" />
</LinearLayout>
```
替换为:
```java
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:drawableStart="@drawable/test" />
```
3、自定义ViewGroup或者include时,使用merge标签、使用ViewStub标签
4、不可见的控件优先使用Gone而不是Invisible
5、RecyclerView: notifyDataSetChanged 对于小更新没必要通知全部刷新
6、...
GPU渲染阶段优化
1、少用一些执行起来比较耗时的Canvas api,比如:
Canvas.saveLayer()
Canvas.drawPath()
Canvas.clipPath()
```java
canvas.save();
canvas.clipPath(mCirclePath);
canvas.drawBitmap(mBitmap, 0f, 0f, mPaint);
canvas.restore();
```
替换为:
```java
// one time init:
mPaint.setShader(new BitmapShader(mBitmap, TileMode.CLAMP, TileMode.CLAMP));
// at draw time:
canvas.drawPath(mCirclePath, mPaint);
```
2、 Bitmap uploads

bitmap在同步上传到GPU的过程中消耗时间,主线程是阻塞的,可以根据控件大小优化bitmap大小等。
3、减少过度绘制
- 移除不需要的背景
- 优化布局的层级,不要有过多的View堆叠
- 自定义View使用clipRect减少过度绘制,比如

-
减少透明度的使用,使用alpha会导致先绘制正常的像素,再进行混合:
1、TextView想要文字透明可以给textColor添加透明度而不是整个TextView设置alpha
2、ImageView 透明使用 setImageAlpha
3、自定义控件 的话设置paint透明度
另外,alpha的使用还会显著影响GPU的渲染性能,因为设置alpha的View会先绘制在离屏缓存,再绘制到屏幕上。原因
主线程耗时操作优化
1、不要在主线程执行耗时操作...
2、IPC的调用会阻塞主线程,注意
3、不要在onDraw等位置创建大量临时对象,会造成大量的GC,stop the world